Парсер сайтов по ключевым словам, Что такое парсинг и как правильно парсить
Написано более трёх лет назад. Александр Шестаков 30 января Lenkep Recruitment. Скачать демо-версию парсера почт из поисковой системы по списку ключевых запросов.
Фильтруем по красному цвету и получаем список урлов, где есть блок с выводом квартир, но нет столбца с ценами!
Таким способом на сайте можно быстро найти и выгрузить выборку необходимых страниц для различных задач. На примере сайта www. Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, текст которого нам нужно выгружать.

То есть. Заполнение происходит через «. Справа выбираем Extract Text будет собирать текстовое содержимое класса. Если бы у вас был элемент, который вложен в другой класс то есть наследуется , то вы бы просто прописали последовательно.
Для того, чтобы не парсить весь сайт целиком, вы можете ограничить область поиска с помощью указания конкретного раздела, который нужно парсить.
Далее парсим сайт, вбив в строку свой урл. Теперь в Excel чистим файл от пустых данных, так как не на всех страницах есть подобные блоки, поэтому данных нет. После фильтрации мы рекомендуем для удобства сделать транспонирование таблички на второй вкладке, так ее станет удобнее читать. Получаем итоговый файл:. Таким образом, решаем сразу 2 задачи:. У парсеров даже есть специальные алгоритмы, которые сразу помечают и классифицируют ошибки по типам, облегчая работу SEO специалиста. Но бывают ситуации, когда с сайта необходимо извлечь содержимое конкретного класса или тега.
Для этого на помощь приходит язык запросов XPath. С помощью него можно извлечь с сайта только нужную информацию, записать ее в удобный вид и затем работать с ней. Данные взяты из официальной справки. Там вы сможете увидеть больше примеров. Если вы хотите собрать адреса электронной почты с вашего сайта или веб-сайтов, XPath может быть следующим:. Запросы чувствительны к регистру, поэтому, если «SEO Spider» иногда пишется как «seo spider», вам придется сделать следующее:.
Команда будет превращать в нижнем регистр весь найденный якорный текст, что позволит сравнить его с «seo spider». Следующий XPath будет извлекать контент из определенных элементов div или span, используя их идентификатор класса. Вам нужно будет заменить example на название своего класса. Поэтому если хочется быть всемогущим и выгружать все что душе угодно, то нужно изучить язык запросов XPath. В предыдущем примере мы показали, как парсить с помощью CSSPath, принцип похож, но у него есть свои особенности.
Для элементарного понимания, таким образом в коде зашифрована вложенность того места, где расположен текст. И мы получается будем проверять на страницах, есть ли текст по этой вложенности. Выглядит это так:. На скрине мы оставили вариант парсинга того же текста, но уже с помощью CSSPath, чтобы показать, что практически все можно спарсить 2-мя способами, но у Xpath все же больше возможностей.
Для реализации задуманного мы воспользуемся уже известными нам методами извлечения данных с помощью CSSPath и XPath запросов. Заходим на любую страницу товара, нажимаем F12 и через кнопку исследования элемента смотрим какой класс у названия товара. При проверке выяснилось, что таких элементов 9 на странице. Поэтому нам нужно уточнить запрос, указав класс вышестоящего элемента. Запрос CSSPath будет выглядеть вот так.
Если хотим получить цену через XPath, то также через исследование элемента копируем путь XPath. Важно выбирать Extract Text , чтобы получать именно текст искомого элемента, а не сам код. После парсим сайт. То, что мы хотели получить находится в разделе Custom Extraction. Подробнее на скрине. Задача: — Поиск страниц, на которые нет ссылок на сайте, то есть им не передается внутренний вес.
Для этого у вас должны быть подтверждены права на сайт через GSC. В отчете мы получим страницы, которые она не обнаружила на сайте, но нашла в Search Console. Подключаем сервисы гугла к Screaming frog SEO spider. Подключаемся к Google Search Console.
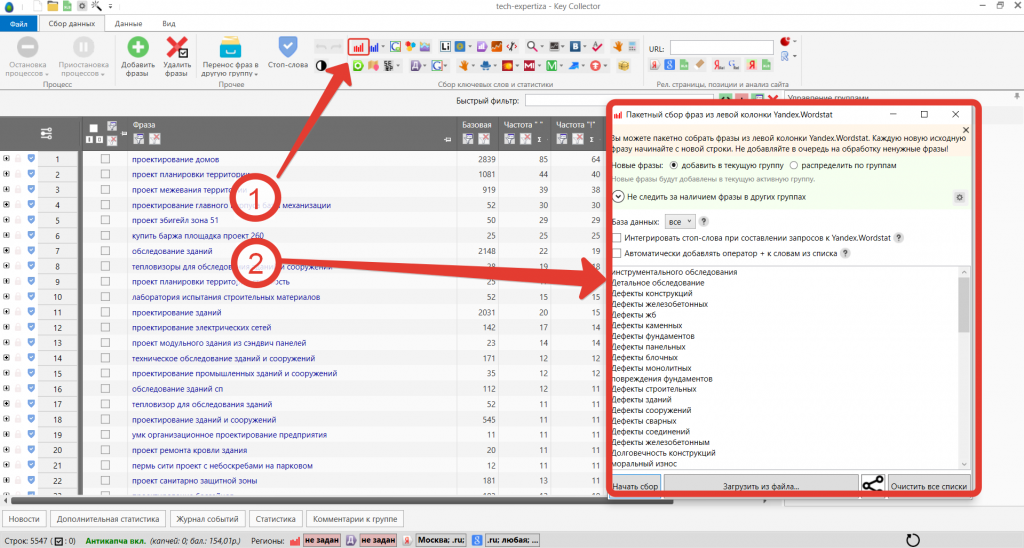
В окошках, указанных выше нужно найти свой сайт, который вы хотите спарсить. С GSC все просто там можно вбить домен. А вот с GA не всегда все просто, нужно знать название аккаунта клиента.
Возможно потребуется вручную залезть в GA и посмотреть там, как он называется. Тут ничего нового. Если нужно спарсить конкретный поддомен, то в Include его добавляем и парсим как обычно.
Когда сбор информации завершится, то можем приступать к выгрузке нужного нам отчета. Открываем получившийся отчет. Получили список страниц, которые известны Гуглу, но Screaming frog SEO spider не обнаружил ссылок на них на самом сайте.
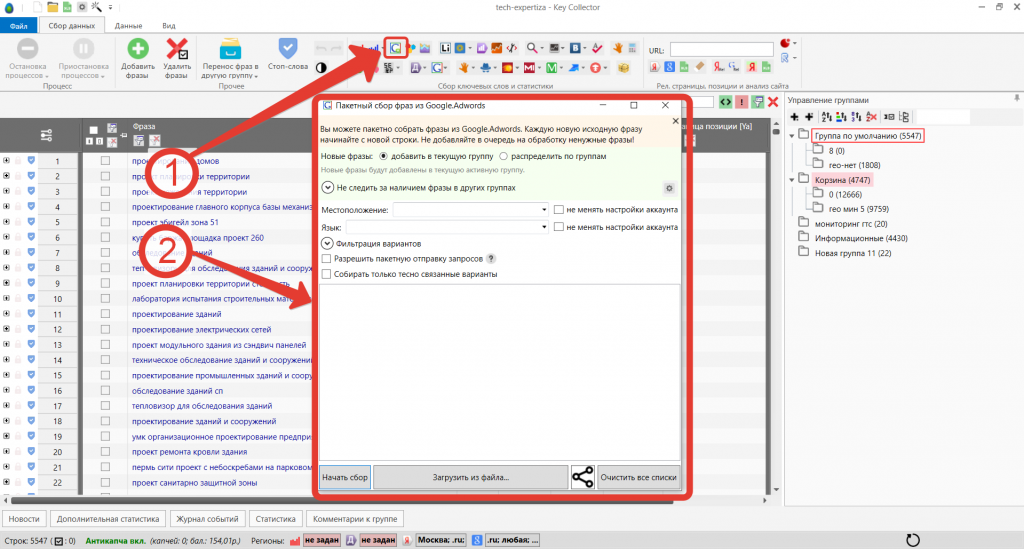
Возможно тут будет много лишних страниц которые отдают или код ответа , поэтому рекомендуем прогнать весь этот список еще раз, используя метод List. После парсинга всех найденных страниц, выгружаем список страниц, которые отдают код.
Получение данных парсером — семантический анализ исходного массива информации. Программа разбивает его на отдельные части лексемы : слова, словосочетания и т. Парсер проводит их грамматический анализ, преобразуя линейную структуру текста в древовидную синтаксическое дерево. Такая форма упрощает «понимание» информационного массива компьютерной программой и бывает двух типов:. Также результат работы парсера может представлять собой сочетание моделей. Программа действует по одному из двух алгоритмов:.
Выбор конкретного метода парсинга зависит от конечной цели. В любом случае, парсер должен уметь вычленять из общего массива только необходимые данные, а также преобразовывать их в удобный для решения задачи формат. Станьте веб-разработчиком и найдите стабильную работу на удаленке. К недостаткам парсеров можно отнести не всегда релевантный анализ данных. Однако в большинстве случаев это зависит от возможностей программы, качества ее настройки пользователем.
В большинстве случаев информация, выдаваемая парсером, требует незначительной обработки для дальнейшего использования. Парсинг применяется в любых областях, где требуется проанализировать и систематизировать большой объем данных:. В веб-разработке и продвижении используется большое количество бесплатных и платных программ для парсинга сайтов.
К числу самых популярных относятся:. Распространено мнение, что парсинг сайтов как минимум неэтичен, а в некоторых случаях и незаконен. Действительно, парсеры собирают информацию с чужих веб-ресурсов, баз данных и других источников. Однако в большинстве случаев сведения находятся в открытом доступе, то есть использование программ не нарушает закон.
Противозаконным может стать применение данных, например:. В целом, парсинг не нарушает нормы законодательства и этики. Автоматизированный сбор информации позволяет сделать сайт и реализуемый с его помощью продукт более удобным для клиентов. Веб-разработчик — мастер на все руки.